


“One night, a young IT student ventured too far… Lost in the darkest corners of the digital realm, he stumbled upon “the code”. Entranced by its power he clicked ‘execute’. And in his ignorance, awakened an ancient evil.
IT enthusiasts from all corners of the world – unite! As the Fellowship of Code, we will defend our digital realm from the Witch of Shadows and her Army of Darkness.
To further destabilize our defenses, The Witch of Shadows unleashed a biological virus onto our world. Due to these circumstances, we are forced to make our final stand from the comfort of our homes with a digital headquarter to organize our defense.”
With that story, Hack the Future introduced its new event and theme of 24th November 2020. HTF is a yearly event just for final-year IT-students so they can get in contact with specific IT companies. It’s an event focused on a variety of IT challenges and networking.
Choose a challenge and a Team!
Because the Fellowship of Code wanted about the same number of people for each challenge, we all had to choose our top 3. According to the number of registrations, it might have been possible that you didn’t get to your first choice.
You could choose between several challenges. The topics were very varied so there was a challenge for everyone. There were more consultancy topics like SAP and BI, but also programming topics like .NET and Java, as well as security and AI topics.
I choose Deep Learning & NLP, .NET, and Security as my top 3. As you guys might already know, I am very interested in AI so NLP was an obvious choice. Besides, you didn’t even need to have experience yet. My second choice was .NET because I love the .NET framework and the description of the challenge sounded fun. Lastly, I chose Security because of my current education and because I want to do a CTF every year and haven’t done one this year yet.
But choosing my top 3 wasn’t the hardest part. I still needed a partner in crime who wanted to do the same things as me. Luckily my friend Olha was down to be in the same team with my top 3, although she does consultancy and was thus more interested in challenges like BI and SAP.
While registering, we got asked a weird question; they wanted to know what our shoe size was. We already knew we would get a box of surprises if we participated in the challenge, so we started guessing what things we would get – maybe sandals or slippers?
We also had to choose a cool name for our team. Olha and I aren’t that good at inventing cool and creative team names, so eventually, I came up with Girls@HowestTI. That way we both represented women in IT and our school.
Get ready!
A week before the start of the event, we got a message telling us that we were selected to join the Fellowship of Code and what challenges we got. I was very happy to see that Olha and I were selected to do the NLP challenge. I was looking forward to finally try out something AI-related with the help of some coaches.

The Friday before the event started, Olha got her mystery box, while I got mine only on the next Monday. But it was kinda worth the wait because I got socks – which explained the shoe size – a small box of cornflakes, instant noodles, a protein bar, an energy drink, a webcam cover, and an HTF sticker.
The same Monday, we all got a link to our digital headquarter. It was a virtual event platform from Thola. It looked very nice! There were several rooms, and everything was in a medieval theme with trolls, elves, witches, and wizards. The setting was a castle with a main entrance and separate rooms for every challenge.
Defining our strategy…
At 9 am, we all gathered in the ceremony room for the live welcome stream. The hosts explained the story and the theme once again and also showed us how the virtual platform worked. They told us that the teams who convinced the jury of their challenge the most would win the grand award, a noise-canceling headset. The teams that were able to win over the hearts of the audience would get the public award – a mystery prize that would be revealed to us at the end of the event.
At 9:20 am, it was time to gather in our challenge room to get a briefing on our mission. Our goal was to find trolls in the programming subreddit. Unfortunately, the trolls were smart enough to hide their posts by merging the fantasy subreddit with the programming one. But because the trolls hid malicious code in their posts, they could still be recognized by the comments full of anger. The goal was to POST all the names of the trolls to an API.
After those two short briefings, it was time to define our strategy. Both me and my teammate Olha didn’t have any experience with NLP yet, so we had no idea how to begin program-wise. But we immediately had an abstract idea of how we would get to a solution.
Our idea was very straightforward. We would classify every post as “programming” or “fantasy”. The posts that were classified as “programming” would be filtered based on the sentiment of the comments. The authors from the remaining posts would be submitted as “trolls”.
Let’s start hacking!
Olha and I had a difficult start because of our inexperience. We were thus very gratified one of the coaches checked up on us to give us some tips.
After that, we looked up on the internet what libraries exist in Python. Olha eventually found TextBlob, a very beginner-friendly Python library with good documentation. As a classifier, we used Naive Bayes.
We started by making separate models for the titles of the posts and their comments in different files. Unfortunately, this took a lot of time because the TextBlob needed tuples, while the data we got was just a file with a bunch of objects. So we had to find a way to convert those objects into tuples. But eventually, just before our lunch break, we had two working models, ready to be combined into a real program.
Merging two models into a working program
After my lunch break, I quickly combined our two models into a working program. As soon as Olha came back, we quickly reread our code and added the function to POST our results to the API.
And then we hit run for the first time…
We didn’t know what to expect, but we knew our approach was okay. Our first score was 20%. Not bad for a first try, but we needed a higher score (we really wanted to win). Our program definitely needed some improvements.
Around that time, the coaches came for a second time to check up on us. One of them gave us the advice to look at the accuracy of our classifier. And so we did. In the original separate files, we tested the accuracy of our two models. Surprisingly, both accuracies came back as 87%, so that couldn’t be the problem. The problem had to be how we combined the two.
After looking very closely at every function of our main program, we noticed a small mistake in how we classified our comments. Due to copy-paste from the separate files, we had forgotten to adapt our code to the format of the Reddit data. After that small bug fix, we got a score of 30%. Quite some improvement for such a small mistake, but we weren’t there yet.
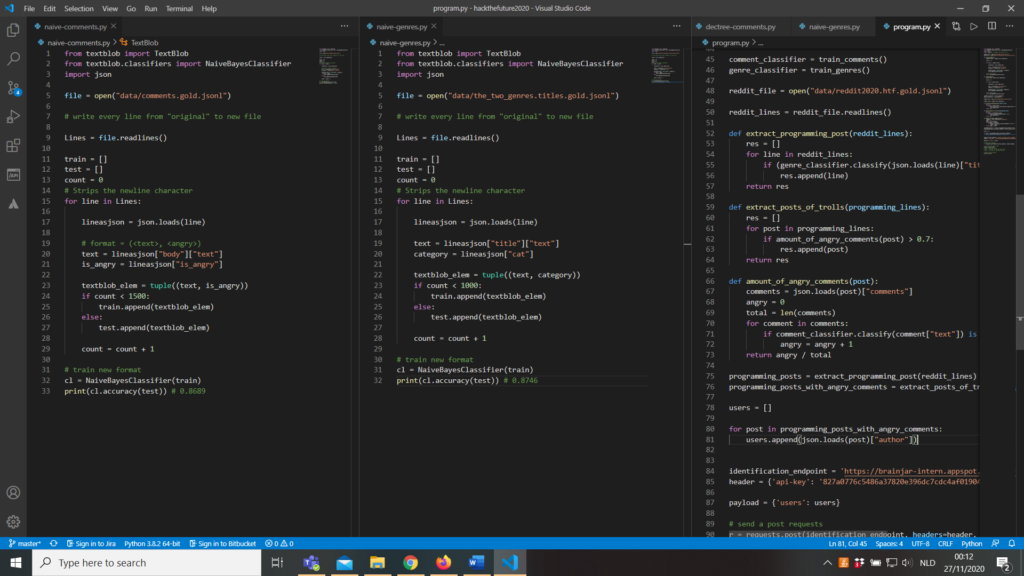
Last adaptations…
In the last hour, we also noticed that we still classified every post as a post from a troll as soon as they had one angry comment. Of course, this seemed wrong, so we started implementing a threshold of 50% on the number of angry comments.
And this is where it went uphill very quickly. Every call to the API took quite some time because we trained our model over and over again every time we ran our code. But when the results came back, we were shook – in a good way. We went from a score of 30% immediately to a score of 75%! We were definitely on the right track, so with trial and error, we tried to find the correct threshold and ended with one of 70% that gave us a score of 88%.
After that, our time was almost up, so we needed to wrap it up for our presentation. While Olha made the PowerPoint, I tried to find a better classifier. I could only find one classifier that didn’t give errors I couldn’t fix because of my inexperience. But unfortunately, that classifier – the Decision Tree – was 3% less accurate than the one we were already using. So in the last 10 minutes, we just finished our PowerPoint and divided our text.
Showing our results
At 4 pm, we all gathered in the call of our challenge. There the coaches thanked us for our participation and asked us in what order we wanted to do our presentation. The majority chose from the lowest to the highest score on the leader board, and so it happened.
It was enthralling to hear the approaches of the other groups and how they learned from their mistakes.
The scores of the first group were all very low, but when we got to the top 4 teams, the scores took huge leaps. The team on place 4 had a score of 42%. They had made two good models for their titles and comments but didn’t have enough time to correctly combine the two. We ended third after KeukenRobots jumped over us with a score of just 1% higher than us. They found a way to make their Naive Bayes model just a little more accurate than ours by removing a validation step. And then it was time for the best team for this challenge. P=PN managed to get a score of 91%, a very high score, but also just 3% higher than ours!
We were all shook how close to each other we all ended. Without any experience, Olha and I managed to get to the top 3, just 3% lower than the best team!
The great winners of the challenge
Our scores weren’t the only thing that determined who would win the grand award. No, based on both the high scores and the presentations, the jury (our coaches) decided who won. While waiting for the award ceremony, we could also vote for our top 3 projects from our competitors. The team with the most votes would get the public award.
At 6 pm, all contestants gathered back in the ceremony room to hear the winners of the headsets and the mystery prize.
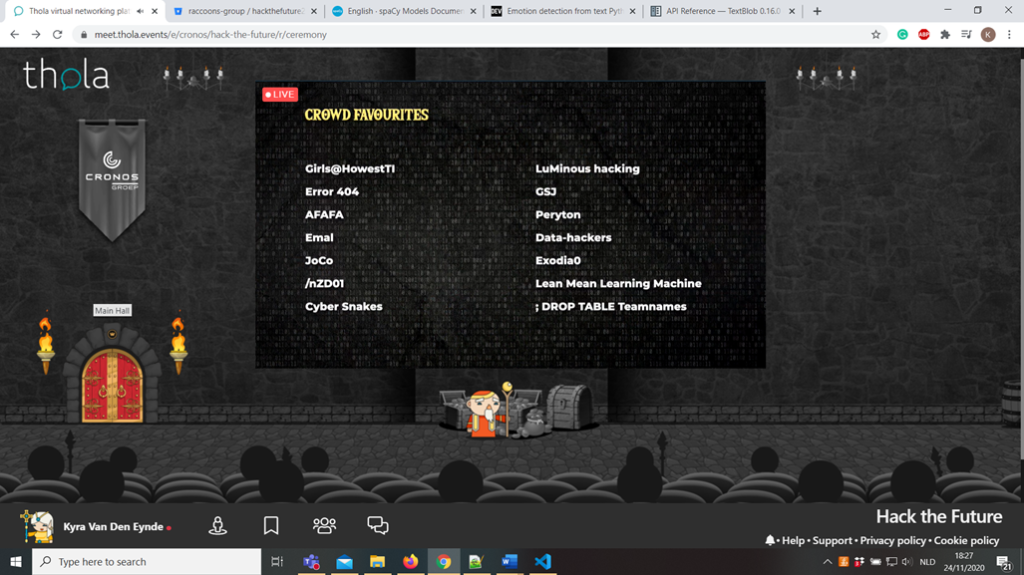
First, they announced all the favorites of the juries per challenge. Unfortunately, Olha and I didn’t win the grand award, but in an email the next day the coaches explained to us that it was a tough decision and then motivated their decision. I really appreciated that because that way they showed acknowledgment of our hard work.
Lastly, the hosts of the event announced all favorites of the public all at once. Olha and I were thrilled to see we did win the public’s prize. I think we really deserved it after all our hard work and with our excellent results. We won a giant cup to drink coffee, tea, or soup from.
An educational day
One big thing I learned from today that experience doesn’t necessarily mean being better in something than someone who has no experience. Besides, inexperience shouldn’t stop you from trying new things. Who knows how much talent you have for it or how much you will learn from it!
Just do IT! — pun intended 😉