


After learning a lot about computer vision last week, it was time for another branch in AI. This week’s session was all about Natural Language Processing (NLP). Again we got a lot of new information and some demos.
This session was a lot more difficult to follow along. We got a lot of info at a fast rate, but it was all very interesting. And luckily we can rewatch the stream as many times as we want.
note: This is the third event in a series of 4. Please read my first post about the October Sessions to learn more about getting started in AI. Or read my second post to learn more about computer vision.
22nd October – Natural Language Processing
When we think about Natural Language Processing, most of us will think about chatbots. But NLP is much more than that. In this session, we, as viewers, got exposed to different implementations of NLP along with their advantages and disadvantages.
Here are some resources they provided during the session of this week:
- website with free courses on data science
- website of Explosion, with info about spaCy, Prodigy, and Thinc
- GitHub repository with project templates of spaCy
- documentation of spaCy v3
- free course (videos and slides) for spaCy
VMware’s bug management with NLP
One very consuming task that a lot of companies that provide services have to do is the classification of reviews of their users. This classification is needed to group every notified bug to see how many users have this problem and to assign just one developer to a group of bugs so the job isn’t done twice.
There already exist some NLP programs that can classify texts or that can see certain similarities between 2 texts. But VMware couldn’t use those because it has its own jargon and that jargon isn’t known by any existing NLP. So VMware had to make its own.
Josh Simons started his presentation with a summary of what VMware does. Most of us might link VMware to virtual machines, but that’s not the only thing the company is known for. They provide all kinds of products that make virtualization possible.
Recently VMware tried to combine machine learning (ML) with its virtualization products for review analysis, log anomaly detection, chatbots, code analysis, etc. But the company’s many specific products and jargon make it very difficult to use existing models. At first, they used word vectors to define their own NLP model, but that one didn’t have context-awareness. That’s why they then used the pre-trained BERT model from Google and trained that model further to create vBERT. vBERT is thus VMware’s specific NLP model with context-awareness, but with a larger footprint.
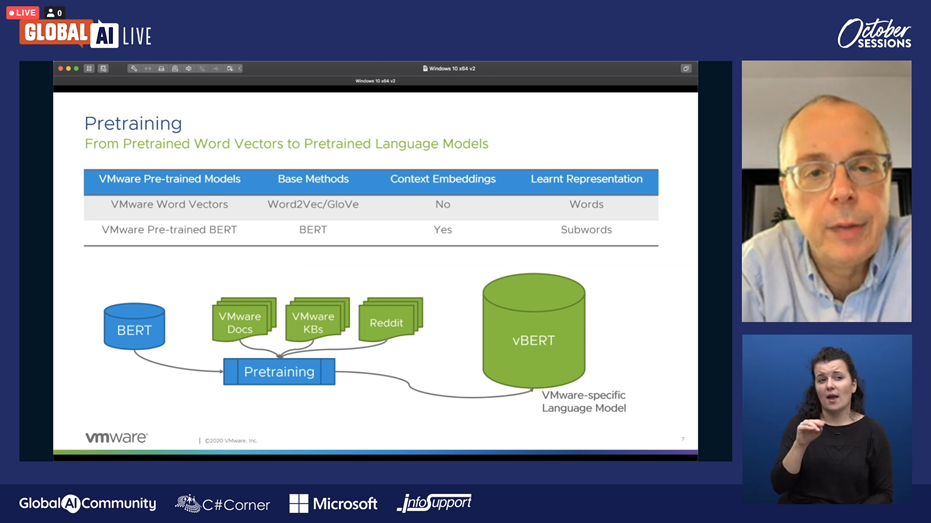
Josh told us both the model based on the word vectors and vBERT work very well. But because of vBERT’s large footprint, he gave us the advice to not always just jump on the latest and greatest, but to go for the most basic solution that does everything you want.
Josh then talked about Bugzilla, a tool they use to merge related bugs in their bug database. The tool detects text similarities in their users’ reports within a time window of 56 days. It then groups those bug reports per product or family of products.
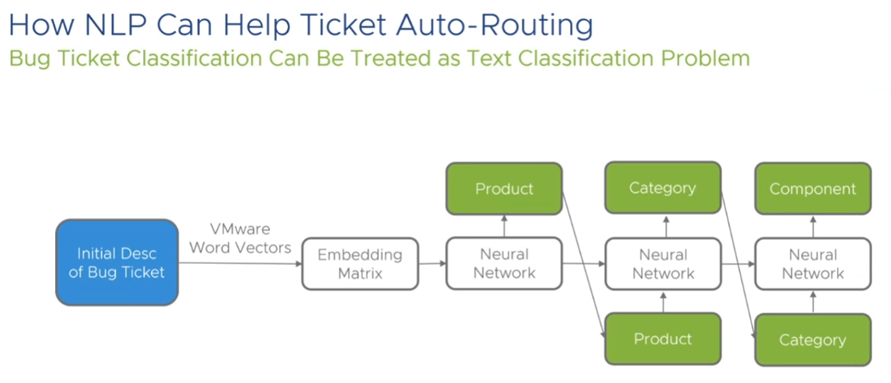
Bugzilla has both advantages and disadvantages. A big asset of this bug classification tool its decrease in working time and its increase in user experience because the bugs are fixed faster. A big disadvantage is that, although they use 3 neural networks for their classification, when a bug is misclassified it takes way longer to fix it.
Josh ended his presentation by giving us some advice on bug classification tools. He told us to focus on finding duplication because not only the severity of the bug but also how many users complain about the bug define its priority. Lastly, Josh wanted to share that using very similar yet different bugs as test data is the best approach to train this kind of model.
Versbot: the story of a self-learning business chatbot
A lot of companies have some sort of chatbot that can answer some basic questions about the company. This is an easy and fast way to answer the client’s questions without the need for human assistance until it’s needed.
Versbot is one of those business chatbots, but this one lets the company make changes to the chatbot in a very easy way. And the best of all? It’s free.
Elron Bandel explained to us that the main goal of Versbot was to decouple the business knowledge from the Q&A expertise. This way users don’t have to think about the way the chatbot works. They just have to fill in a complete explanation of their business. After that, they can test the chatbot and make changes were needed.
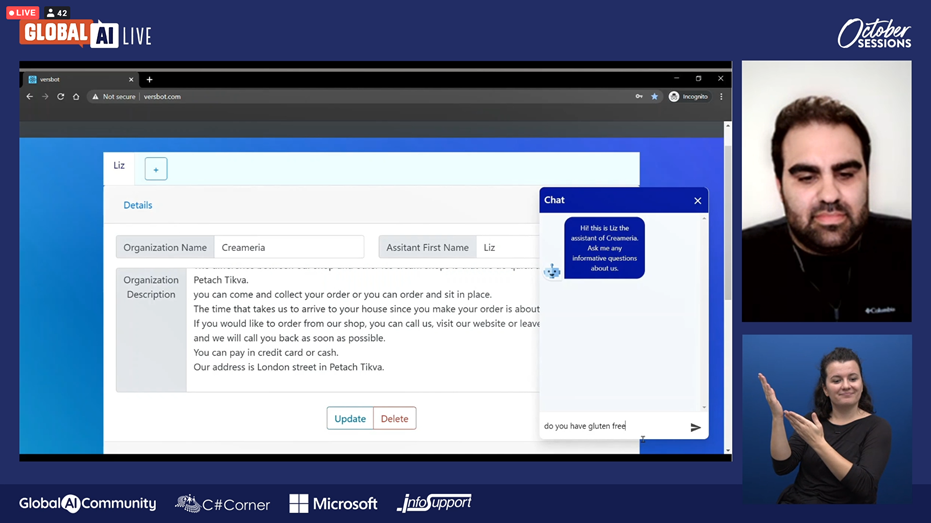
Versbot uses SQuAD (Stanford Question Answering Dataset) to train and to classify its data. Later a new version of SQuAD was released. SQuAD2 can give an answer that explains to the customers that there is no answer to their question. SQuAD would have tried to answer the question anyway and would thus have answered something completely wrong.
One question I had after Elron’s presentation was how chatbots handle typos or maybe even grammar mistakes. I thought you had to train your model up to a certain level with “wrong” questions to let it get used to getting questions with mistakes like that. But I was all wrong. Grammar mistakes don’t matter – which makes sense since NLP models read words, not sentences. But even typos are no problem. NLP models generalize what they “read” which means they can read through mistakes just like we can.
The people in the chat had some interesting questions as well. Someone asked what would happen if someone asked an out-of-context question. Elron simply answered the AI model was programmed to give a predefined answer or to ask for human assistance in case something like that happens. Another question was if they would add actions to the answers of the chatbot. Elron told us that, for now, chatbots only ask for contact info but that chatbots certainly will have more actions in the future.
The problems in modern NLP
We use NLP constantly in our everyday life. NLP is in our autocomplete and our automatic grammar correction and translation. Even when we search for something on the Internet, NLP is used. We can’t think about life without it.
But those are the things that already work very well. Other implementations of NLP still need a lot of work. Think about question answering and dialog. Yes, we have chatbots, but those are quite primitive in comparison to our autocomplete or automatic grammar correction. Text summarizing and automatic image capturing also need some improvement.
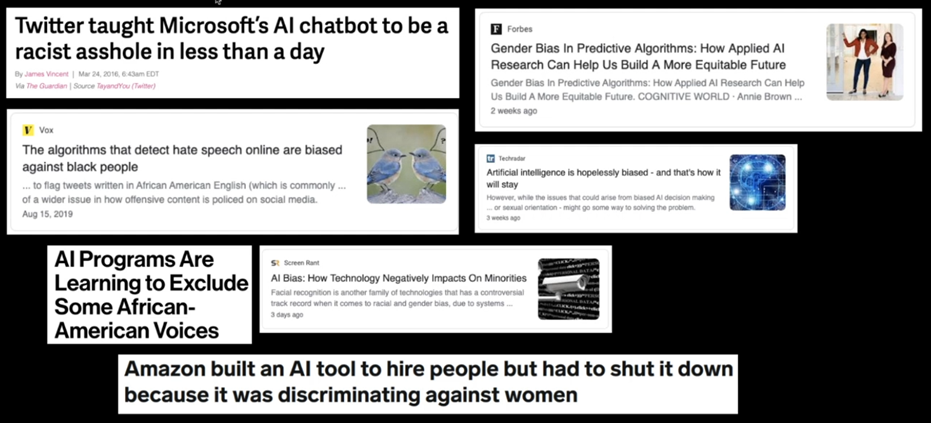
NLP has a lot of problems. We as humans use too many parameters, and the numbers are increasing every day. Google’s GShard for instance used 600 billion parameters as of Augustus 2020. Two other problems that are caused by us are the energy consumption and the bias of the models we create. The latter was discussed in every session because it is very important to know that every AI model only knows what we teach it.
But not all problems with NLP are caused by humans. Some things are still just too difficult to implement. One example of that is inference. When given a premise sentence it is very difficult to judge the correctness of a hypothesis because to do so, NLP needs knowledge about word meanings, understanding of syntax, and commonsense reasoning. Which takes us to the last big problem of NLP: interpretation. AI still can not think like humans so it has no interpretation. It performs very well with only a part of the input, but it fails to generalize and takes everything very literally.
We have come a long way but we still have an even longer way ahead of us. We already succeeded at making NLP models that seamlessly learn I/O mapping, that do not need to be trained from scratch, and that are context-sensitive. But we need to make them smaller, unbiased, and interpretable by using fewer training examples. They have to generalize outside their training domain and need to solve the task instead of learning data-specific shortcuts.
The widely used spaCy and its new version
One of the biggest disadvantages of NLP models is that they are mainly focused on English. spaCy is very different in that. spaCy is a Python library that, as of now, supports 15 different languages (English, Chinese, Japanese, and some European languages like Dutch and Italian).
Ines Montani, the co-founder of Explosion, was the next speaker. Her company specializes in developer tools for ML and NLP, from which spaCy is probably the most popular office tool library. They also have a data annotation tool called Prodigy to create data sets. The company just released the prerelease of spaCy’s new version, 3.0.
# install spaCy v3 (nightly pre-release)
pip install spacy-nightly --preInes’ presentation was prerecorded because she already guessed her Wi-Fi would be bad. On the one hand that was a good thing because that way the audio was clearer. But on the other hand it made it more difficult for me to follow along because she talked way faster than she probably would have if she would have talked live.
Ines’ talk about the library spaCy she helped develop. spaCy is an NLP library for Python that uses neural networks for transformer-based pipelines. Transformer models are a form of neural network architectures, only more scalable and accurate, and more GPU power efficiently.
Using transformer-based models makes a big difference in your performance because a transformer only has to run once, even if it exists of a lot of different components.
Transformer-based pipelines are an example of a rather complex way of arranging your pipelines. The transformer itself introduces several options. And then you have the other components that need to connect to the transformer and set up the other options. There are many ways for this configuration to go wrong. spaCy isn’t the only ML model that has to think about this. Every ML model is sitting on a big pile of configuration.
ML models exist of many simple layers of configurations. Settings are thus everywhere. It’s difficult to align all the default values of different functions. spaCy’s configuration is based on Python’s built-in config pile and modules with a few extra specific extensions. spaCy uses JSON to pass the values. It also uses dot notation in the section names to make those readable. The configuration is resolved bottom-up so every object gets only the configuration it needs itself.
You’re not bound to only spaCy’s built-in functions. It’s easy to add functions using the decorator. The configuration file will validate itself by looking for errors.
Even the installation of this library is very easy. If you package the model using the spaCy package command it can be installed via pip.

spaCy is also very flexible. It exists of trainable, rule-based components. This makes it possible for its users to choose which component they want to update during training instead of retraining the whole model every time.
Besides all that, another important thing that is possible with spaCy do is model customization. This library can communicate with models like PyTorch, TensorFlow, and MXNet via ML library Thinc. Thinc works as an interface layer between spaCy and other ML libraries by wrapping their models and acting as a shim.
After her very profound presentation, Ines Montani answered some questions of the viewers. Someone asked if Explosion is working on making spaCy explainable. Ines told us she thinks that would be a great addition to their already readable config files. She thinks it will be more possible and easier with their new version.
Panel discussion
As usual, the session ended with a panel discussion. This time they focused on some pain points NLP still has, some of which that were already discussed in previous sessions as well.
One thing wanted to emphasize was that NLP models will never know everything. That’s why NLP needs different approaches and many specialized models.
One topic that keeps coming up is bias awareness, one of the biggest problems in AI right now because “what comes in, comes out” according to Sammy. Vared also gave us the advice to really think about what models are a good idea to train and what models not.
Vared then also told us she is a supporter of making AI models publicly available because, yes, it is easy to implement from scratch, but it’s just so unnecessary. Ines immediately agreed: “You need to protect your data, not your model”
Last but not least, they ended with their vision of the future. They all agreed that models will one day combine language and vision for a maximized user experience.
Something to look forward to or to be afraid of? Let me know what you think!